![]() Last weekend, shadow library Anna’s Archive argued that, for AI companies, access to ‘pirated’ books may be a matter of national security.
Last weekend, shadow library Anna’s Archive argued that, for AI companies, access to ‘pirated’ books may be a matter of national security.
The reasoning behind this controversial take concerns the legal implications faced by U.S. companies if they train AI models using data obtained from shadow libraries. Other countries, however, have fewer reservations, which could give foreign companies a technological edge.
American tech companies are well aware of the potential powers of shadow libraries. Meta, the parent company of Facebook, Instagram and WhatsApp, has never denied its use of these libraries to train early versions of its AI models.
Sued Over Torrenting Allegations
Meta isn’t unique in this. Chinese AI disruptor DeepSeek also publicly admitted to using data from ‘pirate’ sources. To date, however, it’s mostly the major U.S. tech giants that have been taken to court.
A class-action lawsuit filed by authors including Richard Kadrey, Sarah Silverman, and Christopher Golden is one such copyright infringement case. The authors accuse Meta of using their work without permission.
Last month, they filed an amended complaint which included BitTorrent-related allegations. The plaintiffs see this as particularly problematic because BitTorrent users typically upload content to third parties as well.
“Meta downloaded millions of pirated books from LibGen through the bit torrent protocol using a platform called LibTorrent. Internally, Meta acknowledged that using this protocol was legally problematic,” the third amended complaint noted.
“By downloading through the bit torrent protocol, Meta knew it was facilitating further copyright infringement by acting as a distribution point for other users of pirated books.”
Unsealed: Terabytes of Data
These alleged wrongdoings needed to be proven in court so the rightsholders sought access to torrent client logs and seeding data from Meta. The request was denied.
Nonetheless, the rightsholders still managed to obtain torrent-related evidence during discovery. Many of the details were previously sealed, but unsealed copies added to the docket yesterday reveal new information.
Quoting from an internal Meta email thread, the plaintiffs were about to show that the company attempted to source data through Anna’s Archive. While this was tricky because the number of seeders was low, they successfully obtained many terabytes.
“[T]he magnitude of Meta’s unlawful torrenting scheme is astonishing: just last spring, Meta torrented at least 81.7 terabytes of data across multiple shadow libraries through the site Anna’s Archive, including at least 35.7 terabytes of data from Z-Library and LibGen.”
“Meta also previously torrented 80.6 terabytes of data from LibGen,” the plaintiffs state in the unsealed document, referring to an email where Anna’s Archive is referred to by the initials “AA”.
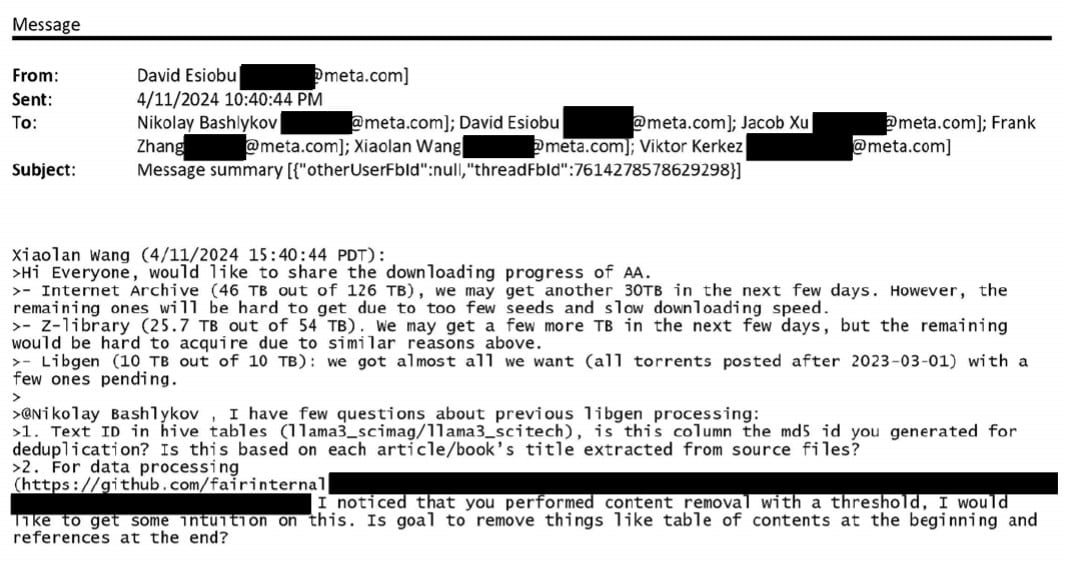
The email, shown above, mentions the Internet Archive as a key source as well, although it’s not a typical shadow library. It provides an overview of the progress made, noting that ‘few seeds’ and ‘slow download speeds’ presented a challenge.
Copyright Concerns?
Meta’s employees were not oblivious to potential copyright concerns. According to the unsealed records, one employee stated: “I feel that using pirated material should be beyond our ethical threshold.”
In addition, there was an internal discussion about not using Facebook infrastructure to torrent, to “avoid[] risk of tracing back the seeder/downloader” to Meta servers.
These comments and references were already known to the plaintiffs, but now enter the public domain. They shed additional light on internal discussions but for Meta, however, these torrenting allegations are not a game changer.
Meta: Fair Use
Last week, Meta filed a motion to dismiss the authors’ claim regarding ‘Removal of Copyright Management Information’ as well as the claim of violating California Penal Code § 502, arguing that neither was properly pled.
Meta did not request dismissal of the copyright infringement complaint, but is confident that it can “debunk this meritless allegation” on summary judgment.
“Plaintiffs do not plead a single instance in which any part of any book was, in fact, downloaded by a third party from Meta via torrent, much less that Plaintiffs’ books were somehow distributed by Meta,” the company writes.
This doesn’t mean that Meta denies using shadow libraries, its argument is that using such data to train its LLM models constitutes fair use under U.S. copyright law.
—
A copy of all relevant documents referenced here are available though Free.law’s Courtlistener
From: TF, for the latest news on copyright battles, piracy and more.
Powered by WPeMatico